
By Arun Kumar
Human–machine interaction today is heavily centered around speech.
Voice assistants, smart speakers, and voice-controlled home automation systems assume that the user can speak clearly and consistently.
However, this assumption excludes an important group of users:
- People with speech impairments
- Individuals who are temporarily unable to speak
- Users with neurological or motor speech disorders
- Situations where speaking is difficult, unsafe, or undesirable
For these users, conventional voice assistants are either unreliable or completely unusable.
This project explores an alternative form of interaction that does not require speech at all.
- Instead of spoken words, the system responds to custom, non-verbal sounds such as taps, clicks, knocks, or simple vocal tones, sounds that are often still possible even when speech is not.
This project explores an alternative approach:
Can a device be controlled using sound intent instead of spoken language?
Proposed Solution:
We propose a voiceless home automation system that operates using:
- Custom non-verbal sounds (taps, clicks, tones)
- Lightweight on-device signal processing
- No internet, no cloud, no speech recognition
The system listens for:
- A wake sound to activate
- A command sound to trigger an action
Each sound is trained by the user, making the system:
- Language-independent
- User-adaptive
- Fully offline
Key Innovations
1. Voiceless Interaction Model
Instead of recognizing words, the system recognizes acoustic patterns:
- Energy envelope
- Spectral distribution
- Temporal consistency
2. This makes the system:
- Faster than speech recognition
- Less computationally expensive
- More robust for embedded hardware
3. On-Device Training
Users can record:
- Wake sound
- Multiple task sounds
These references are stored in non-volatile memory (NVS) and persist across reboots.

Components Required
ESP32S3 Box 3

Circuit Diagram

Hardware Assembly
The ESP32S3 box 3 is mounted on the GPIO dock and the components for testing are connected using the GPIO pins.

Controller:
- ESP32S3 Box 3
- Integrated:
- Microphone
- Audio output
- Touchscreen display
Controlled Loads
- AC Bulb (220V) via relay module
- DC Motor / Fan via MOSFET trigger switch
This allows demonstration of:
- High-voltage AC control
- Low-voltage DC control
- Safe isolation between logic and load
Safety Considerations
- AC loads are isolated using a relay module
- No direct connection between mains voltage and ESP32
- DC motor uses MOSFET switching, not direct GPIO drive
- Audio and control paths are mutually exclusive via mutex locking
Safety was considered at both electrical and software levels.

Code Explanation
The project does not rely on speech recognition or cloud-based voice assistants. Instead, it uses simple, reliable audio signal characteristics to identify intentional sounds made by the user. To separate and identify sounds, the system uses three methods together.
A sound is accepted only if it passes all three checks, which greatly reduces false triggers from background noise.
Overview of the Three Methods
- Loudness Envelope (RMS over time)
- Coarse Spectral Distribution
- Temporal Shape Matching (Correlation)
Each recorded sound (wake sound or command sound) is stored as a reference pattern and later compared against live audio.
1. Loudness Envelope (RMS)
The first method measures how loud the sound is over time. The microphone audio is divided into short frames. For each frame, the system calculates the Root Mean Square (RMS) value, which represents loudness. This produces a loudness envelope, showing how the sound grows and fades.
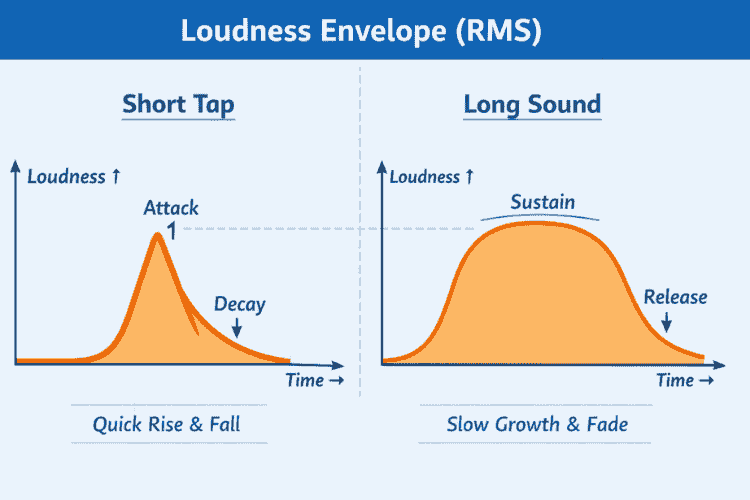
Why this matters: Different intentional sounds have different loudness shapes:
A tap or click rises and falls very quickly
A hum or sustained sound rises slowly and lasts longer
/* RMS = loudness of one frame */
static float compute_rms(int16_t *buf, int samples)
{
double sum = 0;
for (int i = 0; i < samples; i++)
{
float v = buf[i] / 32768.0f;
sum += v * v;
}
return sqrt(sum / samples);
}2. Coarse Spectral Distribution
The second method looks at where the energy of the sound is concentrated.
Instead of performing a full FFT (which is expensive and unnecessary), the signal is split into four coarse frequency bands:
Very low, Low–mid, Mid–high, High. Each band accumulates energy from the audio samples.
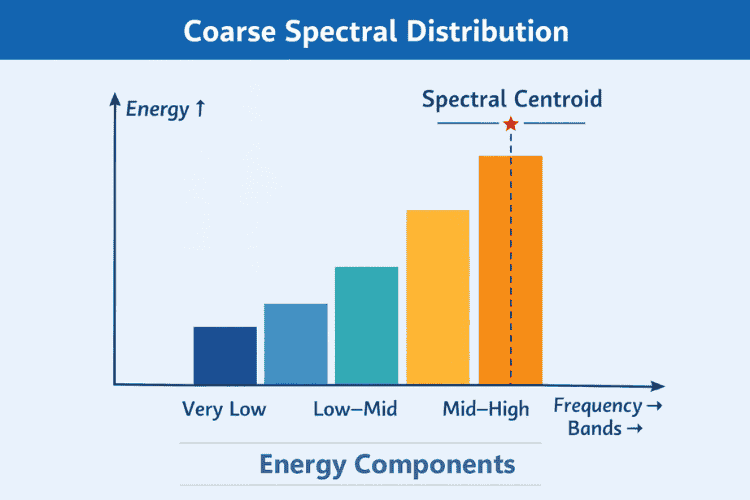
Why this matters: Different sounds excite different frequency ranges:
- Taps and clicks → more high-frequency energy
- Hums and breath sounds → more low-frequency energy
This allows the system to distinguish between: A finger tap, a vocal hum or random background noise.
/* spectral centroid = where energy sits (low vs high freq) */
static float compute_centroid(float bands[SPEC_BANDS])
{
float num = 0, den = 0;
for (int i = 0; i < SPEC_BANDS; i++)
{
num += i * bands[i];
den += bands[i];
}
return (den > 0) ? (num / den) : 0;
}3. Temporal Shape Matching (Correlation)
The third method compares how the sound evolves over time, not just how loud it is. Even if two sounds have similar loudness, their time structure may differ.
To capture this, the system performs
- Correlation between the recorded RMS envelope
- Correlation between the live RMS envelope
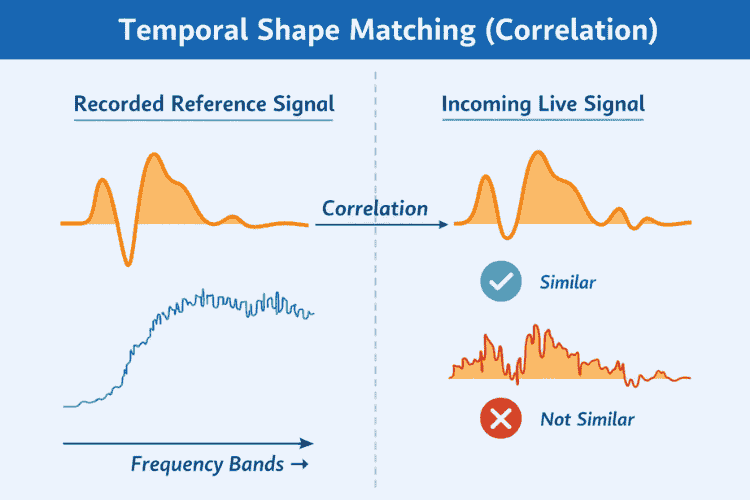
Why this matters: This prevents false triggers such as
- Someone speaking nearby
- Random knocks or table vibrations
- Environmental noise bursts
Only sounds with a similar temporal pattern to the recorded reference are accepted.
/* envelope shape similarity (NOT loudness) */
static float envelope_correlation(float *a, float *b)
{
float num = 0, da = 0, db = 0;
for (int i = 0; i < EVENT_FRAMES; i++)
{
num += a[i] * b[i];
da += a[i] * a[i];
db += b[i] * b[i];
}
return num / (sqrtf(da * db) + 1e-6f);
}User Interface
Main Screen
- Large touch-friendly buttons
- Visual indication of task states
- Status bar showing
- Listening
- Wake detected
- Command executed
Settings Screen
- Record wake sound
- Record task sounds
- Minimal interaction required
The UI is designed for
- Fast interaction
- Clear feedback
- Embedded constraints
This project demonstrates that meaningful human–machine interaction does not require speech recognition.
By combining
- Embedded signal processing
- State-driven software design
- Safe hardware interfacing
we achieve a system that is
- Efficient
- Private
- Robust
- Innovative
This approach opens new possibilities for accessible, offline, and low-cost automation systems.


